Author: Nomic Team
The Nomic Embedding Ecosystem
Over the past several months, Nomic has released a number of State-of-the-Art (SOTA) open source embedding models.
With so many models, it can be hard to know which one to use for your application.
In this post, we'll explore the ecosystem of Nomic Embed models and how they can be used for a wide range of applications.
We will describe the benefits and features of each model, and provide benchmark comparisons to the relevant peer models.
The Ecosystem at a Glance
| Model | Description | Key Features |
|---|
| Nomic Embed v2 | A state of the art multilingual embedder with a mixture-of-experts architecture. | - •SOTA performance on the MIRACL benchmark
- •Support for 100+ languages
- •305M active parameters for efficient inference
- •Open weights, data, and code
|
| Nomic Embed Multimodal | A state of the art multimodal embedder. | - •SOTA performance on the Vidore Benchmark
- •Support for interleaved text and rich visual inputs such as PDFs, screenshots,
- •Open weights, data, and code
|
| Nomic Embed Text v1.5 | The most popular open source text embedder on Hugging Face. | - •Outperforms OpenAI Embeddings on the MTEB benchmark
- •Matryoshka and Binary embeddings for efficient storage
- •137M parameters for efficient inference
- •Open weights, data, and code
|
| Nomic Embed Vision v1.5 | A vision embedder aligned to the Nomic Embed Text v1.5 latent space. | - •Multimodal extension to Nomic Embed Text v1.5
- •Strong performance across text, image, and mixed modality search in a unified latent space
- •Open weights, data, and code
|
| Nomic Embed Code | A state of the art code embedding model. | - •SOTA performance on the CodeSearchNet benchmark
- •Supports Python, Javascript, Java, Go, PHP, and Ruby
- •Pair with Nomic CodeRankEmbed-137M efficient inference
- •Open weights, data, and code
|
A state of the art multilingual embedder with a mixture-of-experts architecture.
Key Features:
- •SOTA performance on the MIRACL benchmark
- •Support for 100+ languages
- •305M active parameters for efficient inference
- •Open weights, data, and code
A state of the art multimodal embedder.
Key Features:
- •SOTA performance on the Vidore Benchmark
- •Support for interleaved text and rich visual inputs such as PDFs, screenshots,
- •Open weights, data, and code
The most popular open source text embedder on Hugging Face.
Key Features:
- •Outperforms OpenAI Embeddings on the MTEB benchmark
- •Matryoshka and Binary embeddings for efficient storage
- •137M parameters for efficient inference
- •Open weights, data, and code
A vision embedder aligned to the Nomic Embed Text v1.5 latent space.
Key Features:
- •Multimodal extension to Nomic Embed Text v1.5
- •Strong performance across text, image, and mixed modality search in a unified latent space
- •Open weights, data, and code
A state of the art code embedding model.
Key Features:
- •SOTA performance on the CodeSearchNet benchmark
- •Supports Python, Javascript, Java, Go, PHP, and Ruby
- •Pair with Nomic CodeRankEmbed-137M efficient inference
- •Open weights, data, and code
| Model | Description | Key Features |
|---|
| Nomic Embed v2 | A state of the art multilingual embedder with a mixture-of-experts architecture. | - •SOTA performance on the MIRACL benchmark
- •Support for 100+ languages
- •305M active parameters for efficient inference
- •Open weights, data, and code
|
| Nomic Embed Multimodal | A state of the art multimodal embedder. | - •SOTA performance on the Vidore Benchmark
- •Support for interleaved text and rich visual inputs such as PDFs, screenshots,
- •Open weights, data, and code
|
| Nomic Embed Text v1.5 | The most popular open source text embedder on Hugging Face. | - •Outperforms OpenAI Embeddings on the MTEB benchmark
- •Matryoshka and Binary embeddings for efficient storage
- •137M parameters for efficient inference
- •Open weights, data, and code
|
| Nomic Embed Vision v1.5 | A vision embedder aligned to the Nomic Embed Text v1.5 latent space. | - •Multimodal extension to Nomic Embed Text v1.5
- •Strong performance across text, image, and mixed modality search in a unified latent space
- •Open weights, data, and code
|
| Nomic Embed Code | A state of the art code embedding model. | - •SOTA performance on the CodeSearchNet benchmark
- •Supports Python, Javascript, Java, Go, PHP, and Ruby
- •Pair with Nomic CodeRankEmbed-137M efficient inference
- •Open weights, data, and code
|
A state of the art multilingual embedder with a mixture-of-experts architecture.
Key Features:
- •SOTA performance on the MIRACL benchmark
- •Support for 100+ languages
- •305M active parameters for efficient inference
- •Open weights, data, and code
A state of the art multimodal embedder.
Key Features:
- •SOTA performance on the Vidore Benchmark
- •Support for interleaved text and rich visual inputs such as PDFs, screenshots,
- •Open weights, data, and code
The most popular open source text embedder on Hugging Face.
Key Features:
- •Outperforms OpenAI Embeddings on the MTEB benchmark
- •Matryoshka and Binary embeddings for efficient storage
- •137M parameters for efficient inference
- •Open weights, data, and code
A vision embedder aligned to the Nomic Embed Text v1.5 latent space.
Key Features:
- •Multimodal extension to Nomic Embed Text v1.5
- •Strong performance across text, image, and mixed modality search in a unified latent space
- •Open weights, data, and code
A state of the art code embedding model.
Key Features:
- •SOTA performance on the CodeSearchNet benchmark
- •Supports Python, Javascript, Java, Go, PHP, and Ruby
- •Pair with Nomic CodeRankEmbed-137M efficient inference
- •Open weights, data, and code
Nomic Embed V2
Nomic Embed v2 is a state of the art multilingual embedder that supports over a hundred languages.
Nomic Embed v2 is the first general purpose embedder to utilize a mixute-of-experts architecture, which enables highly efficient inference by activating only a small subset of the model's parameters at inference time.
This enables it to outperform other general purpose embedders of its size on the multilingual MMTEB benchmark, as shown below:
| Model | Avg | Bittext Mining | Class. | Clust. | Pair Class. | Reranking | Retrieval | STS | $/1M Token |
|---|
| Nomic Embed V2 | 62.48 | 65.12 | 60.37 | 45.59 | 76.33 | 61.72 | 57.26 | 71.03 | $0.01 |
| Voyage 3 Lite | 60.88 | 60.12 | 57.93 | 45.69 | 75.07 | 60.29 | 58.92 | 68.20 | $0.02 |
| OpenAI Embed 3 Small | 58.64 | 50.32 | 55.16 | 46.78 | 76.64 | 59.94 | 52.24 | 69.42 | $0.02 |
| Arctic Embed M 2.0 | 58.44 | 53.73 | 54.38 | 43.02 | 74.86 | 61.67 | 54.83 | 66.60 | $0.01 |
| Model | Avg | Bittext Mining | Class. | Clust. | Pair Class. | Reranking | Retrieval | STS | $/1M Token |
|---|
| Nomic Embed V2 | 62.48 | 65.12 | 60.37 | 45.59 | 76.33 | 61.72 | 57.26 | 71.03 | $0.01 |
| Voyage 3 Lite | 60.88 | 60.12 | 57.93 | 45.69 | 75.07 | 60.29 | 58.92 | 68.20 | $0.02 |
| OpenAI Embed 3 Small | 58.64 | 50.32 | 55.16 | 46.78 | 76.64 | 59.94 | 52.24 | 69.42 | $0.02 |
| Arctic Embed M 2.0 | 58.44 | 53.73 | 54.38 | 43.02 | 74.86 | 61.67 | 54.83 | 66.60 | $0.01 |
Note that we use $/1M Tokens as a proxy for model size, as some models do not report their size publicly.
Further, we also only report publicly available metrics from the MMTEB leaderboard, as some private models do not report all MMTEB subscores.
Nomic Embed v2 also achieves SOTA performance on the MIRACL benchmark, outperforming much larger models including Voyage-3-Large and OpenAI Text Embedding 3 Large.
| Model | Avg | ar | bn | de | en | es | fa | fi | fr | hi | id | ja | ko | ru | sw | te | th | yo | zh |
|---|
| Nomic Embed v2 | 66.0 | 76.7 | 73.6 | 56.6 | 54.7 | 56.3 | 59.2 | 77.1 | 55.8 | 60.5 | 54.2 | 67.0 | 65.9 | 65.2 | 66.3 | 82.6 | 78.3 | 78.3 | 59.5 |
| Voyage-3-Large | 59.5 | 69.6 | 68.3 | 46.2 | 48.4 | 43.8 | 51.1 | 70.8 | 39.8 | 54.8 | 47.2 | 62.3 | 63.9 | 57.8 | 67.9 | 76.7 | 74.5 | 75.6 | 52.1 |
| OpenAI Text Embedding 3 Large | 54.9 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| Model | Avg | ar | bn | de | en | es | fa | fi | fr | hi | id | ja | ko | ru | sw | te | th | yo | zh |
|---|
| Nomic Embed v2 | 66.0 | 76.7 | 73.6 | 56.6 | 54.7 | 56.3 | 59.2 | 77.1 | 55.8 | 60.5 | 54.2 | 67.0 | 65.9 | 65.2 | 66.3 | 82.6 | 78.3 | 78.3 | 59.5 |
| Voyage-3-Large | 59.5 | 69.6 | 68.3 | 46.2 | 48.4 | 43.8 | 51.1 | 70.8 | 39.8 | 54.8 | 47.2 | 62.3 | 63.9 | 57.8 | 67.9 | 76.7 | 74.5 | 75.6 | 52.1 |
| OpenAI Text Embedding 3 Large | 54.9 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
Note that OpenAI does not report their MIRACL subscores, so we only report their average score.
Nomic Embed v2's size makes it ideal for retrieve-rerank workflows, where a small model surfaces a candidate pool which is reordered by a larger, more expensive model.
For a full breakdown of the model, see the Nomic Embed v2 paper or blog post.
To use the model, see the Nomic Embed v2 Hugging Face model page.
Nomic Embed Multimodal
Nomic Embed Multimodal is a state-of-the-art multimodal embedder that supports interleaved text and image inputs, including rich visual documents like PDFs, slides, and Arxiv papers, for accurate multimodal retrieval.
Nomic Embed Multimodal achieves SOTA performance on the Vidore v1 and v2 Benchmark.
| Model | Avg. | ESG Restaurant Human | Econ Macro Multi. | AXA Multi. | MIT Bio | ESG Restaurant Synth. | ESG Restaurant Synth. Multi. | MIT Bio Multi. | AXA | Econ. Macro |
|---|
| ColNomic Embed Multimodal 7B | 62.7 | 73.9 | 54.7 | 61.3 | 66.1 | 57.3 | 56.7 | 64.2 | 68.3 | 61.6 |
| ColNomic Embed Multimodal 3B | 61.2 | 65.8 | 55.4 | 61.0 | 63.5 | 56.6 | 57.2 | 62.5 | 68.8 | 60.2 |
| T-Systems ColQwen2.5-3B | 59.9 | 72.1 | 51.2 | 60.0 | 65.3 | 51.7 | 53.3 | 61.7 | 69.3 | 54.8 |
| Nomic Embed Multimodal 7B | 59.7 | 65.7 | 57.7 | 59.3 | 64.0 | 49.2 | 51.9 | 61.2 | 66.3 | 63.1 |
| GME Qwen2 7B | 59.0 | 65.8 | 56.2 | 55.4 | 64.0 | 54.3 | 56.7 | 55.1 | 60.7 | 62.9 |
| Nomic Embed Multimodal 3B | 58.8 | 59.8 | 57.5 | 58.8 | 62.5 | 49.4 | 49.4 | 58.6 | 69.6 | 63.5 |
| Llama Index vdr-2b-multi-v1 | 58.4 | 63.1 | 52.8 | 61.0 | 60.6 | 50.3 | 51.2 | 56.9 | 68.8 | 61.2 |
| Voyage Multimodal 3 | 55.0 | 56.1 | 55.0 | 59.5 | 56.4 | 47.2 | 46.2 | 51.5 | 64.1 | 58.8 |
| Amazon Titan Multimodal | 20.3 | 18.6 | 20.6 | 14.2 | 33.9 | 8.5 | 10.1 | 22.6 | 21.7 | 32.6 |
| Model | Avg. | ESG Restaurant Human | Econ Macro Multi. | AXA Multi. | MIT Bio | ESG Restaurant Synth. | ESG Restaurant Synth. Multi. | MIT Bio Multi. | AXA | Econ. Macro |
|---|
| ColNomic Embed Multimodal 7B | 62.7 | 73.9 | 54.7 | 61.3 | 66.1 | 57.3 | 56.7 | 64.2 | 68.3 | 61.6 |
| ColNomic Embed Multimodal 3B | 61.2 | 65.8 | 55.4 | 61.0 | 63.5 | 56.6 | 57.2 | 62.5 | 68.8 | 60.2 |
| T-Systems ColQwen2.5-3B | 59.9 | 72.1 | 51.2 | 60.0 | 65.3 | 51.7 | 53.3 | 61.7 | 69.3 | 54.8 |
| Nomic Embed Multimodal 7B | 59.7 | 65.7 | 57.7 | 59.3 | 64.0 | 49.2 | 51.9 | 61.2 | 66.3 | 63.1 |
| GME Qwen2 7B | 59.0 | 65.8 | 56.2 | 55.4 | 64.0 | 54.3 | 56.7 | 55.1 | 60.7 | 62.9 |
| Nomic Embed Multimodal 3B | 58.8 | 59.8 | 57.5 | 58.8 | 62.5 | 49.4 | 49.4 | 58.6 | 69.6 | 63.5 |
| Llama Index vdr-2b-multi-v1 | 58.4 | 63.1 | 52.8 | 61.0 | 60.6 | 50.3 | 51.2 | 56.9 | 68.8 | 61.2 |
| Voyage Multimodal 3 | 55.0 | 56.1 | 55.0 | 59.5 | 56.4 | 47.2 | 46.2 | 51.5 | 64.1 | 58.8 |
| Amazon Titan Multimodal | 20.3 | 18.6 | 20.6 | 14.2 | 33.9 | 8.5 | 10.1 | 22.6 | 21.7 | 32.6 |
Nomic Embed Code
Nomic Embed Code is a 7B parameter code embedding model optimized for code search that achieves state-of-the-art performance on the CodeSearchNet (CSN) benchmark.
The Nomic Embed Code ecosystem also includes Nomic CodeRankEmbed-137M, a highly efficient code embedding model that achieves SOTA performance on the CSN benchmark for size.
Nomic Embed Code can be used as a standalone model, or paired with Nomic CodeRankEmbedr-137M in a retrieve-rerank workflow.
| Model | Python | Java | Ruby | PHP | JavaScript | Go |
|---|
| Nomic Embed Code | 81.6 | 80.5 | 81.9 | 72.3 | 77.1 | 93.8 |
| Voyage Code 3 | 80.9 | 80.5 | 84.6 | 71.7 | 79.2 | 93.2 |
| Nomic CodeRankEmbed-137M | 78.4 | 76.9 | 79.3 | 68.8 | 71.4 | 92.7 |
| OpenAI Embed 3 Large | 70.8 | 72.9 | 75.3 | 59.6 | 68.1 | 87.6 |
| CodeSage Large v2 | 74.2 | 72.3 | 76.7 | 65.2 | 72.5 | 84.6 |
| Model | Python | Java | Ruby | PHP | JavaScript | Go |
|---|
| Nomic Embed Code | 81.6 | 80.5 | 81.9 | 72.3 | 77.1 | 93.8 |
| Voyage Code 3 | 80.9 | 80.5 | 84.6 | 71.7 | 79.2 | 93.2 |
| Nomic CodeRankEmbed-137M | 78.4 | 76.9 | 79.3 | 68.8 | 71.4 | 92.7 |
| OpenAI Embed 3 Large | 70.8 | 72.9 | 75.3 | 59.6 | 68.1 | 87.6 |
| CodeSage Large v2 | 74.2 | 72.3 | 76.7 | 65.2 | 72.5 | 84.6 |
Nomic Embed Text v1.5
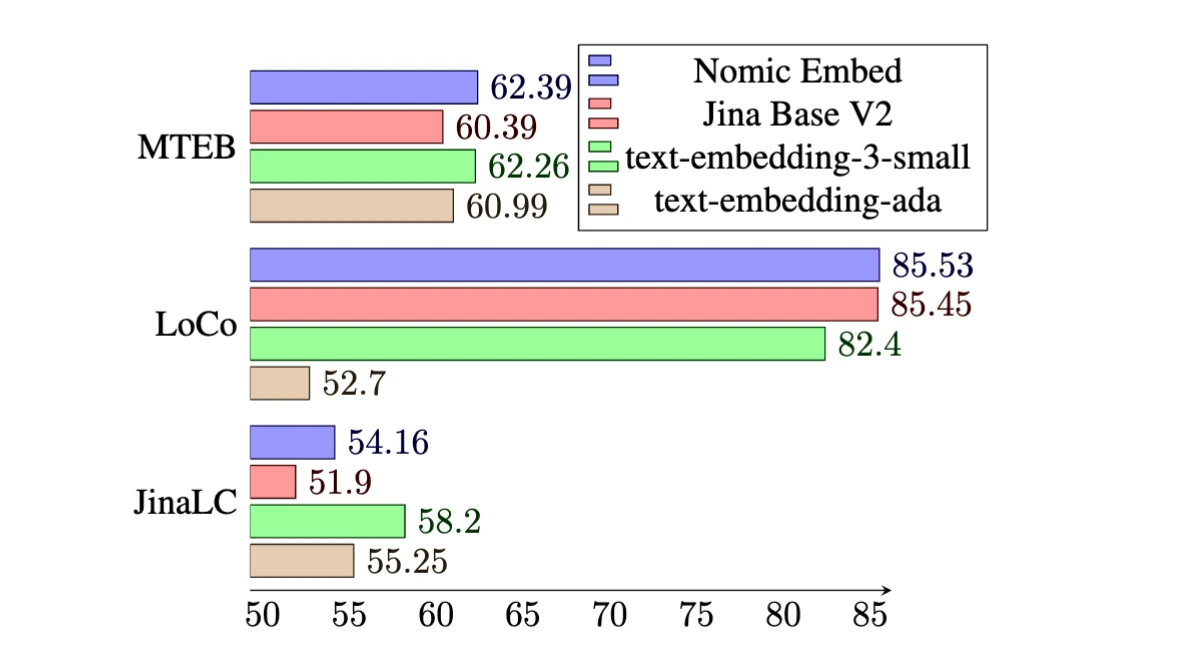
As of the time of this writing, Nomic Embed v1.5 is the most popular open source embedder on Hugging Face, having been downloaded over 35 million times.
It's easy to see why - Nomic Embed Text v1.5 outperforms the industry standard OpenAI Embeddings on the MTEB benchmark, and at only 137M parameters, it's incredibly easy to scale to massive text collections.
Its compact size also makes it ideal for locally running applications - a full precision Nomic Embed v1.5 clocks in at over 100qps on a standard M2 MacBook.
Nomic Embed Text v1.5 also supports two efficient storage formats: Matryoshka and Binary.
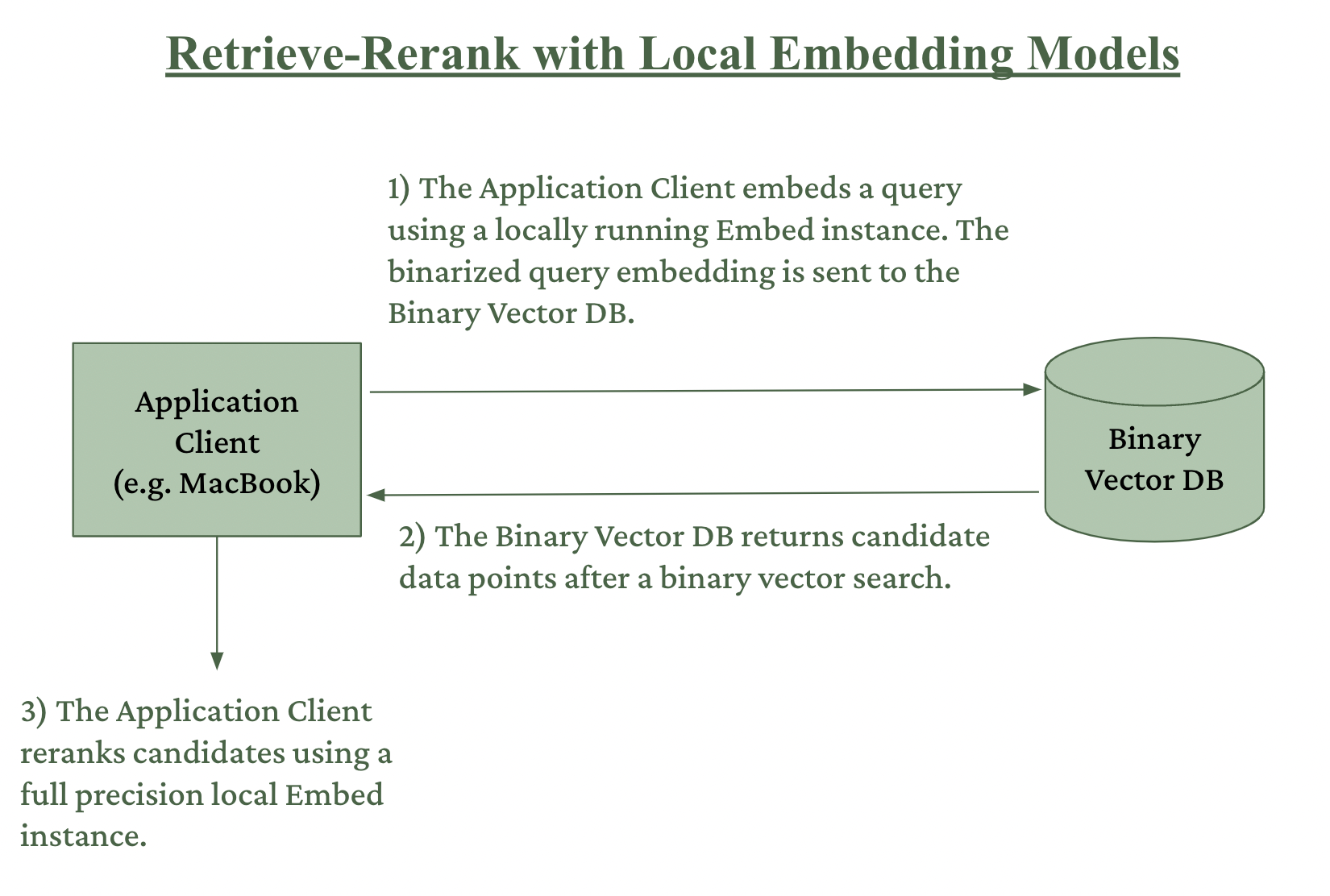
When combined, Nomic Embed's local inference and binary storage capabilities enable a powerful workflow we call Retrieve-Rerank with Local Embedding Models, which reduces vector storage costs by up to 100x with virtually no loss in downstream performance.
We illustrate this binary retrieve-rerank in the figure below:
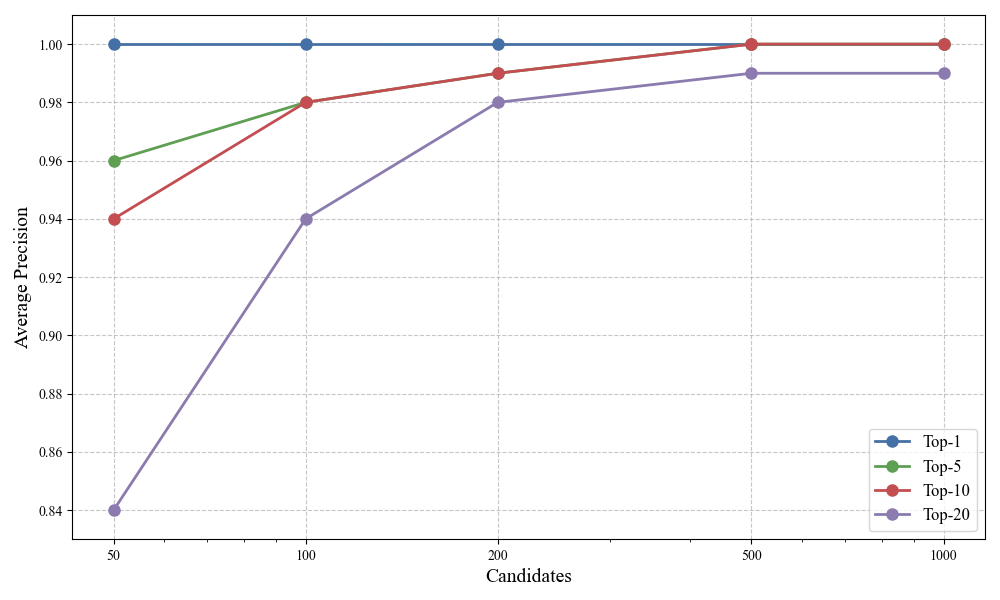
In the chart above, average precision measures how closely the documents surfaced by retrieve-rerank match a full precision retrieval.
From this chart, we can see that the performance of binary retrieve-rerank workflow is virtually identical to the performance of the full precision retrieval.
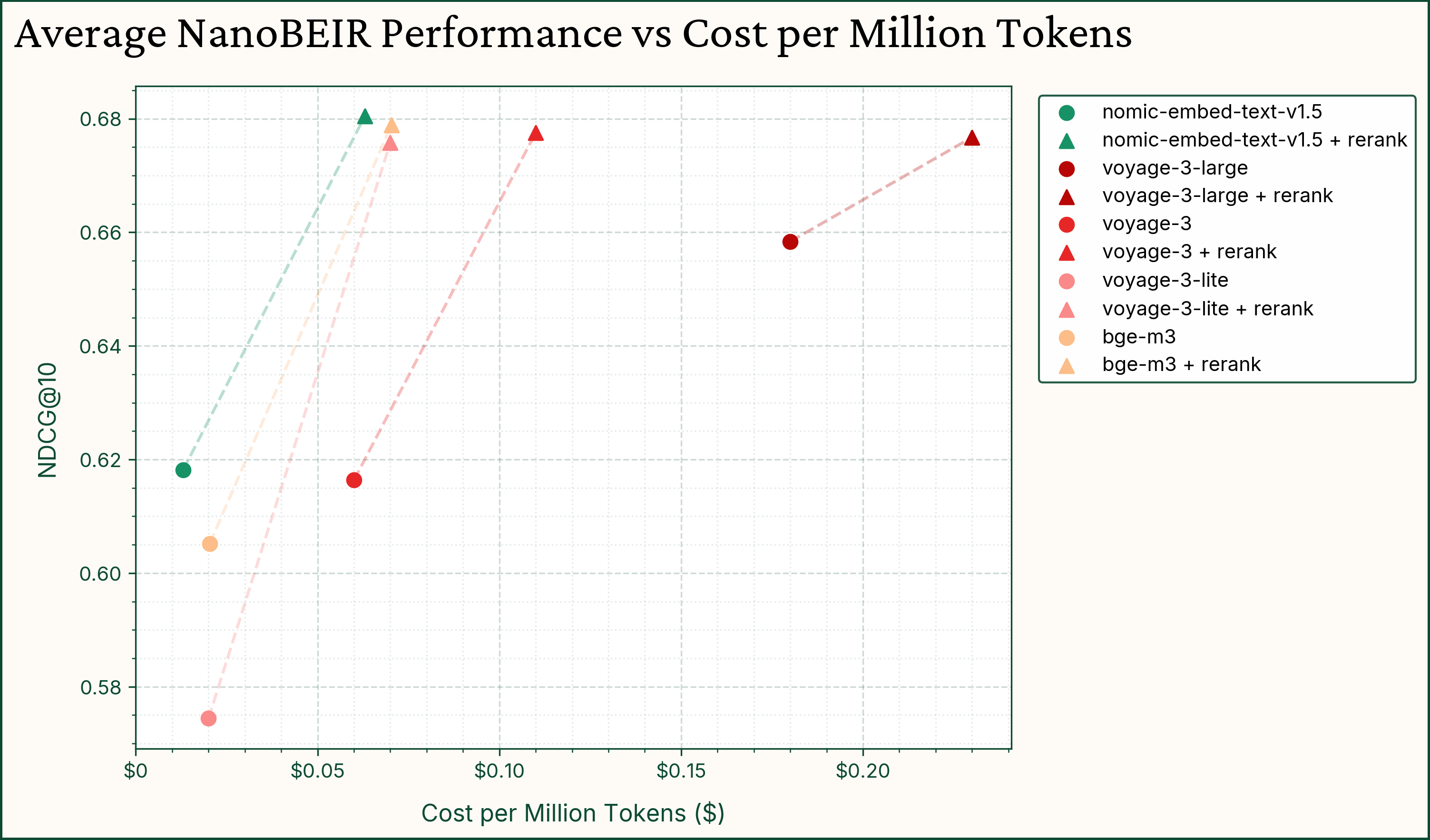
Moreover, Nomic Embed Text v1.5 can be paired with other powerful rerankers to achieve powerful retrieval performance at a fraction of the cost.
For example, Nomic Embed Text v1.5 paired with Voyage-3-Large achieves SOTA performance on the MicroBEIR benchmark at a fraction of the cost of other methods.
For a full breakdown of the model, see the Nomic Embed Text paper or blog post.
To use the model, see the Nomic Embed v1.5 Hugging Face model page.
Nomic Embed Vision v1.5
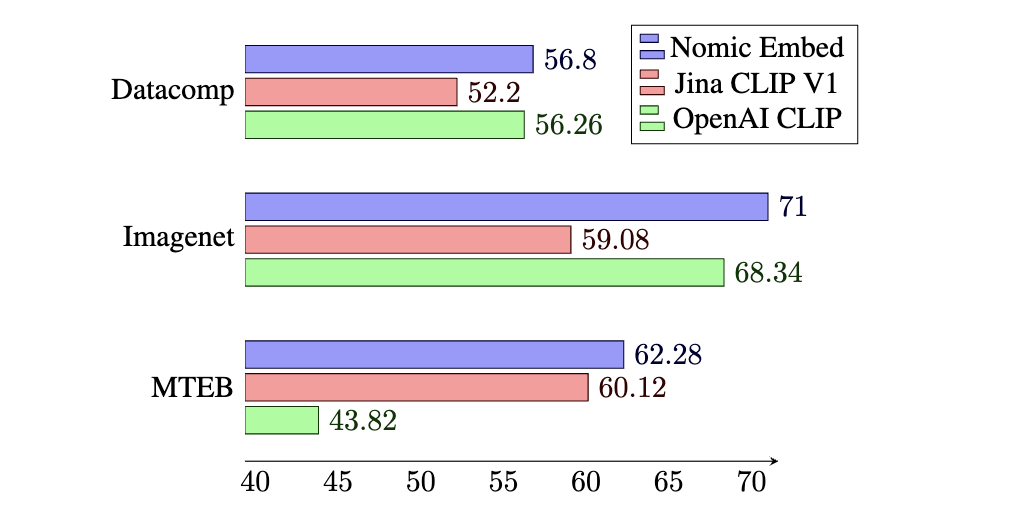
Nomic Embed Vision v1.5 is a vision embedder that is aligned to the Nomic Embed Text v1.5 latent space.
This enables the Nomic Embed 1.5 latent space to achieve strong performance across text, image, and mixed modality search.
This stands in contrast to most CLIP style models, which sacrifice performance on text search to achieve strong performance on image search.
For a full breakdown of the model, see the Nomic Embed Vision v1.5 paper or blog post.
To use the model, see the Nomic Embed v1.5 Hugging Face model page.
Conclusion
In this post, we've explored the Nomic embedding ecosystem - a collection of truly open source state-of-the-art models for text, vision, and code embedding applications.
From the powerful multilingual Nomic Embed v2, to the widely-adopted Nomic Embed Text v1.5, to specialized models like Nomic Embed Vision and Nomic Embed Code, each model is designed to excel at specific tasks while remaining efficient and accessible.
These models demonstrate that it's possible to achieve industry-leading performance while maintaining open access to weights, data, and code.

