Nomic transforms decades of unstructured data into organized, AI-ready knowledge. Empower your teams with domain-specific agentic workflows that accelerate every project, workflow, and decision across your firm's institutional knowledge.
Introducing Nomic Embed: A Truly Open Embedding Model
We're excited to announce the release of Nomic Embed, the first
Open source
Open data
Open training code
Fully reproducible and auditable
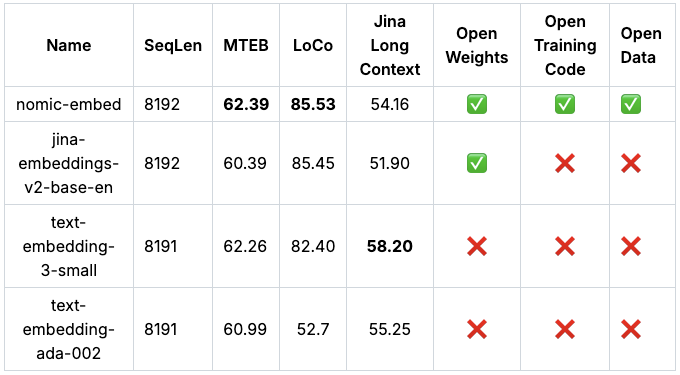
text embedding model with a 8192 context-length that outperforms OpenAI Ada-002 and text-embedding-3-small on both short and long context tasks. We release the model weights and training code under an Apache-2 license, as well as the curated data we used to train the model. We also release a detailed technical report.
Nomic Embed is in general availability for production workloads through the Nomic Atlas Embedding API with 1M free tokens included and is enterprise-ready via our fully secure and compliant Nomic Atlas Enterprise offering.
Text embeddings are an integral component of modern NLP applications powering retrieval-augmented-generation (RAG) for LLMs and semantic search. They encode semantic information about sentences or documents into low-dimensional vectors that are then used in downstream applications, such as clustering for data visualization, classification, and information retrieval. Currently, the most popular long-context text embedding model is OpenAI's text-embedding-ada-002, which supports a context length of 8192. Unfortunately Ada is closed source and it's training data is not auditable.
Top performing open source long-context text embedding models such E5-Mistral and jina-embeddings-v2-base-en are either not practical for general-purpose use due to model size or fail to exceed the performance of their OpenAI counterparts.
Nomic-embed changes that.
How Are Text Encoders Trained?
Text encoders are usually trained with contrastive learning on large collections of paired texts in multiple stages.
At the high level, the Transformer architecture is first pre-trained with a self-supervised MLM objective (BERT), then contrastively trained with web-scale unsupervised data and finally contrastively finetuned with a smaller, curated corpus of paired data.
The first unsupervised contrastive stage trains on a dataset generated from weakly related text pairs, such as question-answer pairs from forums like StackExchange and Quora, title-body pairs from Amazon reviews, and summarizations from news articles.
In the second finetuning stage, higher quality labeled datasets such as search queries and answers from web searches are leveraged. Data curation and hard-example mining is crucial in this stage.
How We Built Nomic Embed
In this blog post, we outline the high level recipe for building nomic-embed. For further details please see our technical report.
Training a 2048 Context-Length BERT
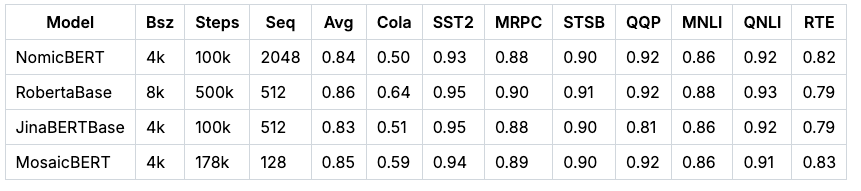
To train nomic-embed, we followed a multi-stage contrastive learning pipeline. We start our model from a BERT initialization. Since bert-base only handles context lengths up to 512 tokens, we train our own 2048 context length BERT, nomic-bert-2048.
We make several modifications to our BERT training procedure inspired by MosaicBERT. Namely, we:
During masked language modeling, we mask at a 30% rate instead of 15%
We do not use the next sentence prediction objective
We evaluate the quality of nomic-bert-2048 on the standard GLUE benchmark. We find it performs comparably to other BERT models but with the advantage of a significantly longer context length.
Contrastive Training of Nomic Embed
We initialize the training of nomic-embed with nomic-bert-2048. Our contrastive dataset is composed of ~235M text pairs. We extensively validated its quality during collection with Nomic Atlas. You can find dataset details in the nomic-ai/constrastors codebase as well as explore a 5M pair subset in Nomic Atlas.
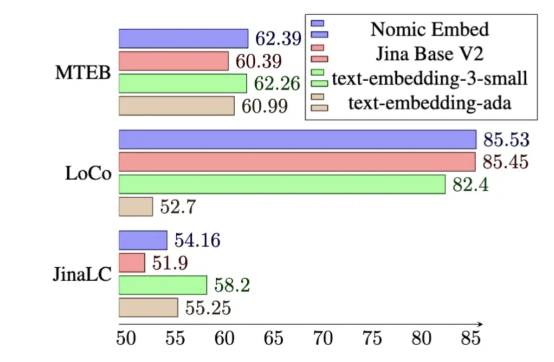
On the Massive Text Embedding Benchmark (MTEB), nomic-embed outperforms text-embedding-ada-002 and jina-embeddings-v2-base-en.
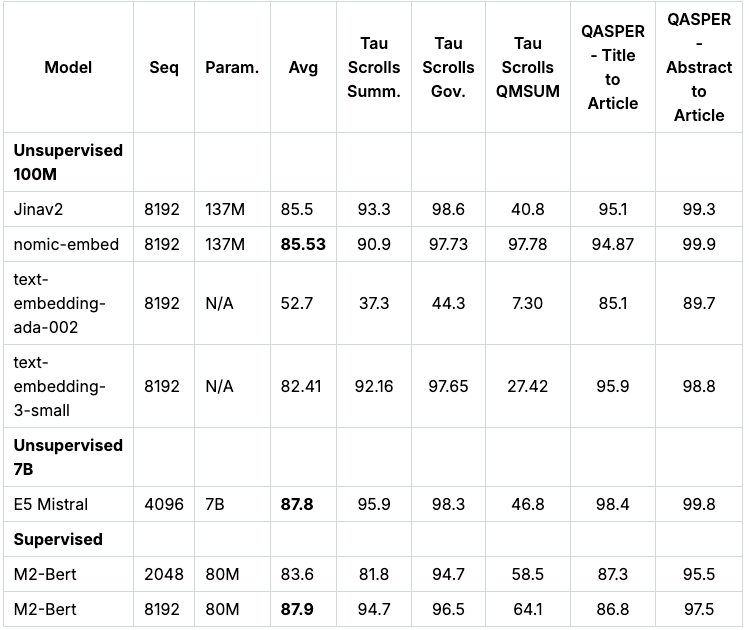
Unfortunately, MTEB doesn't evaluate models on long-context tasks. Therefore, we additionally evaluated nomic-embed on the recently released LoCo Benchmark as well as the Jina Long Context Benchmark.
For the LoCo Benchmark, we split evaluations into parameter class and whether the evaluation is performed in a supervised or unsupervised setting. We bold the top performing model in each split. Nomic Embed is the best performing 100M parameter class unsupervised model. Notably, Nomic Embed is competitive with the top performing models in both the 7B parameter class and with models trained in a supervised setting specifically for the LoCo benchmark:
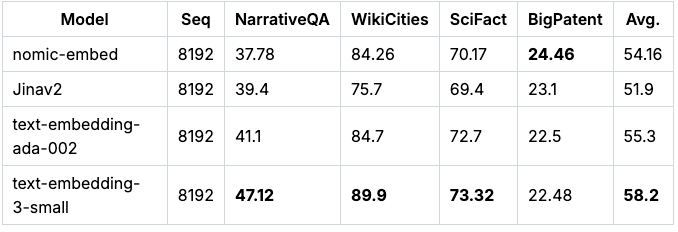
Nomic Embed also outperforms jina-embeddings-v2-base-en in aggregate on the Jina Long Context Benchmark. Unfortunately, Nomic Embed does not outperform OpenAI ada-002 or text-embedding-3-small on this benchmark:
Overall Nomic Embed outperforms OpenAI Ada-002 and text-embedding-3-small on 2/3 benchmarks.
Nomic Embedding API and Atlas Enterprise
We release the Nomic Embed model weights and full-training data for complete model auditability. Nomic recognizes enterprises require fully-auditable AI and we're proud to offer the first performant text embedding model that can achieve it. Contact Nomic to learn about Nomic Atlas Enterprise.
The best option to use Nomic Embed is through our production-ready Nomic Embedding API.
You can access the API via HTTP and your Nomic API Key:
In addition to using our hosted inference API, you can purchase dedicated inference endpoints on the AWS Marketplace. Please contact sales@nomic.ai with any questions.
Data Access
To access the full data, we provide Cloudflare R2 access keys to the buckets containing the data. To get access, create a Nomic Atlas account and follow the instructions in the contrastors repo.
Nomic asks that if you want to use a public inference service for accessing Nomic Embed, you choose the Atlas Embedding API. This allows Nomic to continue driving future open-source AI innovation. Remember, you can always access and run the model without usage restrictions by simply downloading the open-source model weights.