
With the rise in AI code assistants like Cursor and Windsurf, effective code retrieval is critical for improving code generation across large codebases. Existing code embedding models tend to struggle with real-world challenges like finding bugs in Github repositories, likely due to noisy inconsistent data used during training.
As an extension to our ICLR 2025 paper CoRNStack: High-Quality Contrastive Data for Better Code Retrieval and Reranking, we've scaled up and trained Nomic Embed Code, a 7B parameter code embedding model which outperforms Voyage Code 3 and OpenAI Embed 3 Large on CodeSearchNet. Like all of Nomic's models, Nomic Embed Code is truly open source. The training data, code, and model weights are all available on Huggingface and Github under an Apache-2.0 license.
CoRNStack, is a large-scale high-quality training dataset specifically curated for code retrieval. The dataset is filtered using dual-consistency filtering and utilizes a novel sampling technique to progressively introduce harder negative examples during training.
In CoRNStack, we trained and released Nomic CodeRankEmbed, a 137M parameter code embedding model, and Nomic CodeRankLLM, a 7B parameter code reranking model. Now, we've unified the retrieval and reranking models into a streamlined 7B parameter model, Nomic Embed Code.
Nomic Embed Code is a 7B parameter code embedding model that achieves state-of-the-art performance on CodeSearchNet.
Like our previous models, Nomic Embed Code is truly open source. The training data, code, and model weights are all available on Huggingface and Github.
Nomic Embed Code's impressive performance is due to the quality of the training data. Starting with the deduplicated Stackv2, we create text-code pairs from function docstrings and respective code. We filtered out low-quality pairs where the docstring wasn't English, was too short, or that contained URLs, HTML tags, or invalid characters. We additionally kept docstrings with text lengths of 256 tokens or longer to help the model learn long-range dependencies.
After the initial filtering, we used dual-consistency filtering to remove potentially noisy examples. We embed each docstring and code pair and compute the similarity between each docstring and every code example using an out of the box embedding model. We remove pairs from the dataset if the corresponding code example is not found in the top-2 most similar examples for a given docstring.
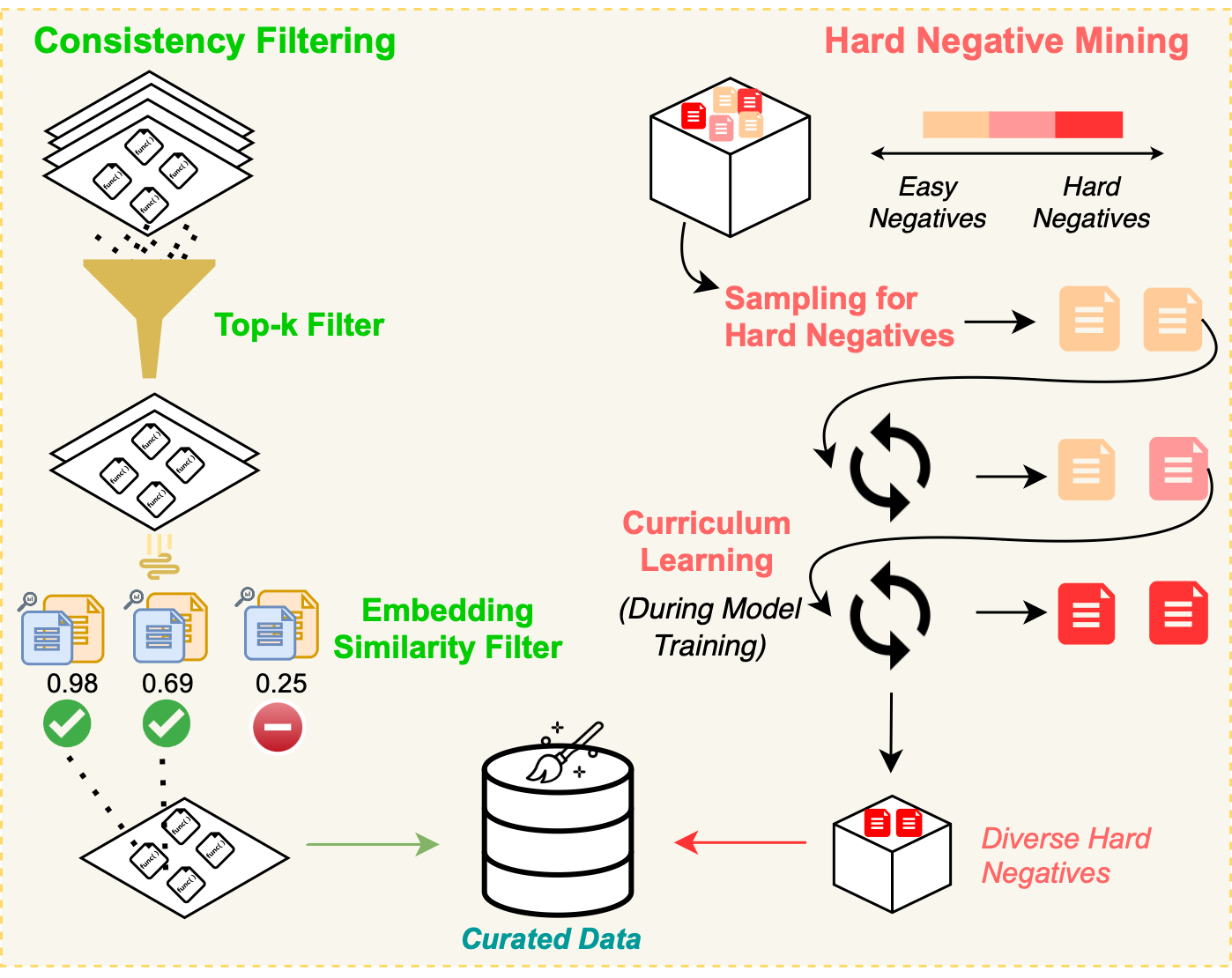
During training, we employ a novel curriculum-based hard negative mining strategy to ensure the model learns from challenging examples. We use a softmax-based sampling strategy to progressively sample hard negatives with increasing difficulty over time.
In this blog post, we've introduced Nomic Embed Code, a 7B parameter code embedding model that achieves state-of-the-art performance on CodeSearchNet. Nomic Embed Code builds on the CoRNStack dataset and training methodology, which are detailed in our ICLR 2025 paper. Code embeddings represent just one part of the Nomic Embed Ecosystem. To learn more about the entire ecosystem, check out our blog.
